Zuverlässigkeitstechnik als Beitrag zur Nachhaltigkeit
Gastartikel vom April 2021 von Prof. Dr. A. Birolini
Professor Emeritus für Zuverlässigkeitstechnik an der ETH Zürich
(Curriculum Vitae: Birolini.ch / ETH Zürich)
Inhaltsverzeichnis
EinleitungGrundbegriffe, Hauptaufgaben
Zuverlässigkeitsanalysen in der Entwicklungsphase
Zuverlässigkeitsprüfungen
Zusammenarbeit mit der Industrie
Ausblick
Literatur
Einleitung
Zuverlässigkeitstechnik ist ein ingenieurmässig stark interdisziplinäres Gebiet, mit dem Ziel zuverlässige und langlebige Bauteile, Geräte und Systeme zu entwickeln und zu fabrizieren unter Berücksichtigung der Nachhaltigkeit, d. h. der Ressourcen-Schonung, der Auswirkung auf die Umwelt sowie der Möglichkeit für Recycling. Sie fordert deshalb einen ausgesprochenen Willen für die Zusammenarbeit mit allen Projektmitgliedern sowie breite Kenntnisse in Ingenieurwissenschaften und Mathematik. Sie ist als selbständige Disziplin in den 50er Jahren im Rahmen von Raumfahrt- und Militärprojekten entstanden. Mitte der 80er Jahre wurde an der ETH Zürich ein Lehrstuhl eingerichtet [1]. Heutzutage wird sie in vielen Hochschulen und Universitäten gelehrt.
Mit der zunehmenden Problematik der Umweltbelastung und der Ressourcen-Verknappung gewinnt das Gebiet der Zuverlässigkeitstechnik stark an Bedeutung. Eine Grundvorlesung im Umfang von einem Semester zu 2 Std. pro Woche sollte deshalb zum Curriculum jedes Ingenieurs gehören. Diese kurze, allgemein zugängliche Darlegung kann für anspruchsvolle Leser/Interessenten mit [2], besser mit [3] oder mit der dort aufgeführten Literatur ergänzt werden.
Grundbegriffe, Hauptaufgaben
Quantitativ gesehen, ist die Zuverlässigkeit R(t) die Wahrscheinlichkeit, dass eine Betrachtungseinheit, neu zur Zeit t = 0, seine geforderte Funktion ausfallfrei während des
Zeitintervalls (0,t) unter gegebenen Bedingungen ausführen wird. Die Notwendigkeit von einer Wahrscheinlichkeit zu sprechen, ist weil alle systematischen Ausfälle vor Beginn der Inbetriebnahme eliminiert sein
sollen/sollten und damit die Ausfälle zufällig auftreten. Zwei Grössen die oft anstelle des Zuverlässigkeitswertes (zwischen 0 und 1) angegeben werden, sind der Mittelwert der ausfallfreien Arbeitszeit
MTTF (Mean Time To Failure) und die Ausfallrate λ(t). λ(t)δt gibt die Wahrscheinlichkeit an, dass die Betrachtungseinheit, neu zur Zeit t = 0, erst
im Intervall (t,t+δt) ausfallen wird. Ist λ(t) zeitunabhängig, d. h. λ(t) = λ, so wird oft MTTF = MTBF =1/λ gebraucht (
MTBF steht für Mean operating Time Between Failures).
Für reparierbare Betrachtungseinheiten werden entsprechend die Reparaturrate μ(t) und die MTTR (Mean Time To Repair), sowie der
Mittelwert für eine präventive Wartung MTTPM definiert. Für diese Betrachtungseinheiten wird neben der Zuverlässigkeit (wie oben definiert, wobei nur Ausfälle auf Systemebene zu
berücksichtigen sind, was im Falle der Anwesenheit von Redundanz zu wesentlich höheren MTTF-Werten führt), auch die Verfügbarkeit PA(t) definiert.
PA(t) ist die Wahrscheinlichkeit, dass die Betrachtungseinheit zur Zeit t seine geforderte Funktion unter gegebenen Bedingungen ausführt (zwischen 0 und t kann sie ausgefallen und repariert worden
sein). Der stationäre Wert PA gibt auch den Prozentsatz der Zeit während dem die Betrachtungseinheit zur Verfügung steht. Oft werden hier auch die Mittelwerte der Arbeitszeiten
MUT (Mean Up Time) und der Ausfallzeiten (für Reparatur oder anders) MDT (Mean Down Time) gebraucht.
Die Aktivitäten zur Sicherstellung der Zuverlässigkeit (inklusive Instandhaltbarkeit und Wartbarkeit) werden in enger Zusammenarbeit mit jener für die
Qualitätssicherung durchgeführt. Für Grossprojekte werden sie oft in einem projektspezifischen Qualitäts- und Zuverlässigkeits-Sicherungsprogramm (RAMS assurance program)
festgelegt, das in der Regel auch die Sicherheitsaspekte berücksichtigt (RAMS steht für Reliability, Availability, Maintainability, Safety). Typische Struktur und Inhalt eines solchen Programms mit einem Vorschlag
für die Zuteilung der Kompetenzen für die Durchführung der entsprechenden Aufgaben werden ausführlich im Kapitel 1.3 und Anhang A3 von [3] dargelegt. Speziell für Grossprojekte werden auch die
logistische Unterstützung in der Nutzungsphase und Kostenbetrachtungen besonders wichtig.
Zuverlässigkeitsanalysen in der Entwicklungsphase
Die Zuverlässigkeit muss in der Entwicklungsphase in ein Produkt (Betrachtungseinheit) hineinentwickelt und während der Fabrikation, Transport und Nutzung aufrechterhalten werden. Das gilt auch für die Sicherheit,
und für reparierbare Betrachtungseinheiten auch bezüglich der Instandhaltbarkeit und Wartbarkeit.
Wichtig für die Sicherstellung der Zuverlässigkeit, Instandhaltbarkeit und Sicherheit sind, neben geeigneten Analysen, auch die Festlegung und Befolgung von
Entwicklungsrichtlinien (Design Guidelines) und die Durchführung von Entwurfsüberprüfungen (Design Reviews). Eine umfassende Liste von Entwicklungsrichtlinien für
Zuverlässigkeit, Instandhaltbarkeit (inklusive ergonomische sowie Sicherheit Aspekte) und Softwarequalität sind im Kapitel 5 von [3] gegeben. Ausführliche Fragenkataloge für Entwurfsüberprüfungen
sind im Anhang A4 von [3] zusammengestellt.
Die Prozedur für die Zuverlässigkeitsanalyse einer nichtreparierbaren Betrachtungseinheit (bis zum Ausfall auf Niveau Betrachtungseinheit) ist in Bild 1 dargestellt.
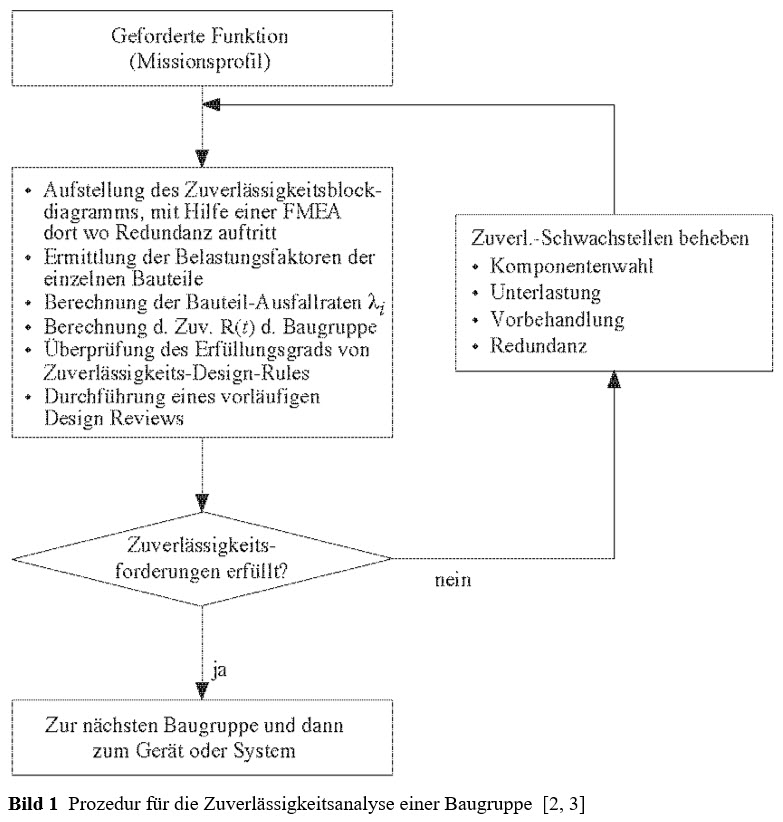 Die Durchführung der FMEA (Failure Modes and Effects Analysis) unterstützt die Ausfallartenanalyse und ist unentbehrlich, wo
Redundanz auftritt oder die Sicherheit im Vordergrund steht [2, 3].
Die Durchführung der FMEA (Failure Modes and Effects Analysis) unterstützt die Ausfallartenanalyse und ist unentbehrlich, wo
Redundanz auftritt oder die Sicherheit im Vordergrund steht [2, 3].
Das Zuverlässigkeitsblockdiagram (ZBD) ist ein Ereignisdiagramm, es gibt die Antwort auf die Frage: Welche Elemente müssen zur Erfüllung der geforderten Funktion funktionieren und welche dürfen ausfallen (Redundanz). Die Aufstellung erfolgt, indem man die Betrachtungseinheit in Elemente zerlegt, die eine klar umrissene Aufgabe erfüllen. Diese Elemente werden dann zu einem Blockdiagramm derart zusammengefügt, dass die für die Funktionserfüllung notwendigen Elemente in Serien- und redundante Elemente in Parallelschaltung erscheinen; die Ausfallart des betreffenden Elements ist dabei zu berücksichtigen (FMEA). Mit dem ZBD wird stets beim höchsten Integrationsniveau (System zur Vereinheitlichung der Bezeichnung) begonnen. Für jede tiefere Stufe wird die entsprechend geforderte Funktion formuliert und das zutreffende ZBD aufgestellt. Dies solange möglich/notwendig ist. Weil das ZBD ein Ereignisdiagram ist, dürfen für jedes Element nur zwei Zustände (gut/ausgefallen) und eine Ausfallart angenommen werden.
Die Berechnung der Ausfallraten am tieferen Niveau des ZBD (Bauteil oder Baugruppe) erfolgt mit Hilfe von etablierten Ausfallratenkatalogen vorhanden in der Regel auf Bauteile-Ebene (siehe z. B. [2.20-2.30] in [3]), oder aus firmeninternen Daten.
Die Berechnung der Zuverlässigkeit der Betrachtungseinheit erfolgt dann mit Hilfe folgender zwei Grundformeln der Wahrscheinlichkeitsrechnung (Pr steht für Wahrscheinlichkeit).
|
Pr{A ∩ B} = Pr{A} Pr{B}, |
für 2 unabhängige Ereignisse A und B |
(1)
|
| Pr{A ∪ B} = Pr{A} + Pr{B}- Pr{A ∩ B } | für 2 beliebige Ereignisse A und B | (2) |
Gleichung (1) kommt zur Anwendung für die Serienschaltung von Elementen, und Gleichung (2) für die Parallelschaltung. Tabelle 1 fasst die Resultate für einige wichtige ZBD-Strukturen zusammen [2, 3].
Zur Betonung, dass die Betrachtungseinheit neu zur Zeit t = 0 ist, wird in [3] das Index S (für System) mit S0 konsequent verwendet. MTTFS0 folgt
dann aus
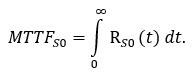 |
(3) |
Für reparierbare Betrachtungseinheiten werden die Bestimmung der Reparaturraten für jedes Element im ZBD, und die Berechnung der vorausgesagten Zuverlässigkeit und Verfügbarkeit der Betrachtungseinheit in der Prozedur von Bild 1 hinzugeführt. Die Berechnung der Zuverlässigkeit und der Verfügbarkeit muss mit Hilfe von stochastischen Prozessen erfolgen. Stochastische Prozesse sind mathematische Modelle für Zufallserscheinungen, die in der Zeit ablaufen, wie z. B. das Auftreten eines Ausfalls. Die Untersuchungen sind besonders einfach, wenn man annehmen kann, dass Ausfallraten und Reparaturraten zeitunabhängig (konstant) sind. In diesen Fällen hat man mit sogenannten (zeithomogenen) Markoff-Prozessen zu tun. Die Verallgemeinerung der Reparaturraten führt zu regenerativen Prozessen mit mindestens einem regenerativen Zustand, und die Verallgemeinerung von Ausfall- und Reparaturraten führt in der Regel zu nicht regenerativen Prozessen mit entsprechenden mathematischen Schwierigkeiten. Anhang A7 von [3] gibt eine umfassende Einführung in all diese Prozesse und Kapitel 6 von [3] wendet diese Prozesse zur Untersuchung der Zuverlässigkeit und der Verfügbarkeit üblicher Zuverlässigkeitsstrukturen an.
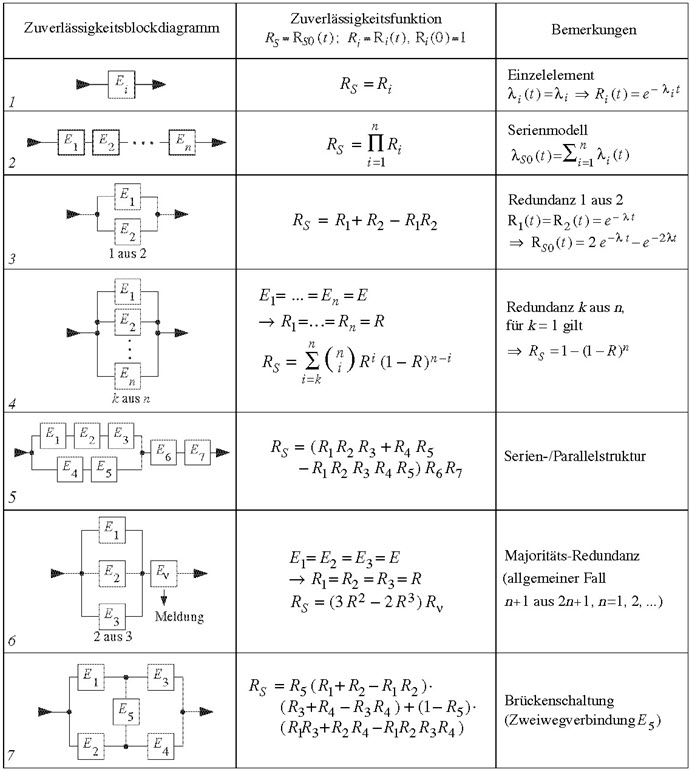 Tabelle 1
Tabelle 1
typische Strukturen von Zuverlässigkeitsblockdiagrammen und entsprechenden Zuverlässigkeits- Funktionen (Annahmen: nichtreparierbar (bis zum Systemausfall), heisse Redundanz, unabhängige Elemente neu zur Zeit t = 0; der Index S bezieht sich auf die Betrachtungseinheit (System), und steht für S0 weil neu zur Zeit t = 0, i auf das Element Ei) [2, 3]
Im Folgenden wird das Beispiel einer Redundanz 1 aus 2 mit Serienelement Ev kurz betrachtet [2, 3]. Die getroffenen Annahmen sind:
- 2 gleiche Elemente E1 = E2 = E in heisser Redundanz (das Reserveelement in der Redundanz ist wie das Arbeitselement belastet);
- konstante Ausfallraten λ,λv und Reparaturraten μ,μv;
- nur eine Reparaturmannschaft steht zur Verfügung und für das Serienelement Ev gilt die Priorität der Reparatur (eine allfällige Reparatur auf E
1 oder E2 wird beim Ausfall von Ev unterbrochen und Ev wird repariert);
- bei einem Ausfall auf Systemebene (System down, d. h. Ev oder E1 und E2 sind ausgefallen) wird der Betrieb unterbrochen, kein weiterer Ausfall kann auftreten und es wird repariert mit Priorität der Reparatur auf Ev.
Bild 2 gibt das entsprechende Diagramm der Übergangswahrscheinlichkeiten in (t,t+ δt). Das Diagramm der Übergangswahrscheinlichkeiten in (t,t+ δt) vom Bild 2 kann leicht interpretiert werden:
- in Z0 und Z2 ist das System im Betrieb (up);
- in Z1, Z3, Z4 ist das System ausgefallen (down, und kein weiterer Ausfall kann auftreten);
- in Z0 sind alle Elemente neu;
- in Z1 ist das Serienelement Ev; ausgefallen, wird repariert und das System ist down;
- in Z2 ist das Arbeitselement oder das Reserveelement ausgefallen, er wird repariert und das arbeitsfähige Element führt den Betrieb weiter; in diesem Zustand kann neben der Reparatur des ausgefallenen Elements auch (mit einer viel kleineren Wahrscheinlichkeit) entweder das Serienelement Ev ausfallen (das System geht in Z3), oder das jetzige Arbeitselement ausfallen (das System geht in Z4);
- infolge der angenommenen konstanten Ausfall- und Reparaturraten, ist das System ohne Gedächtnis, damit ist in (t,t+δt) der Übertritt von einem Zustand zum anderen unabhängig von t (d. h. vom ganzen Zeitverhalten in (0,t)) und nur abhängig vom Zustand zur Zeit t (λδt,μδt usw.).
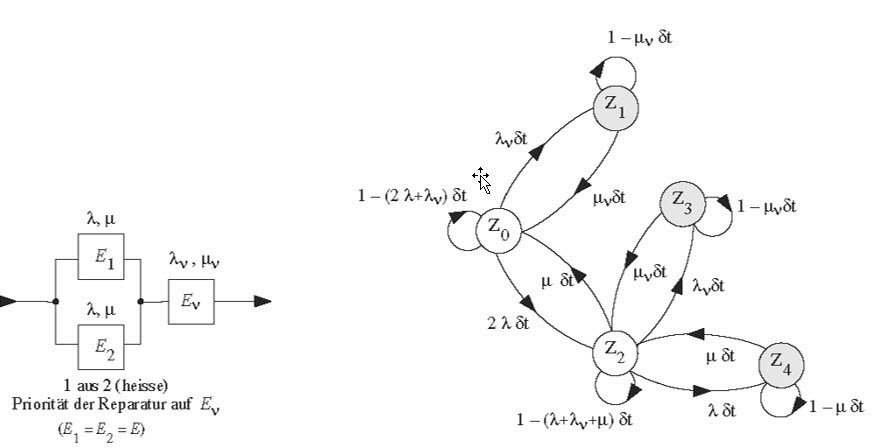
Bild 2 Zuverlässigkeitsblockdiagramm und Diagramm der Übergangswahrscheinlichkeiten in (t,t+δt) einer heissen Redundanz 1 aus 2 mit Serienelement (Vergleichselement / Umschalteinrichtung)
Ev [2, 3]
Infolge der angenommenen zeitunabhängigen Reparaturrate μ wird in Z4 die Reparatur für das ausgefallene Arbeits- oder Reserveelement in Z0 neu gestartet, das gleiche gilt bei einem
Übergang von Z3 zu Z2. Man sieht damit, wie die Annahme einer konstanten Reparaturrate unrealistisch ist. Deshalb wurde in [3] die Verallgemeinerung der Reparaturraten systematisch untersucht bis an die
Grenze, wo der involvierte Prozess keinen einzigen regenerativen Zustand mehr enthält (Untersuchungen mit nicht regenerativen Prozessen können schwierig werden).
Die Berechnung der Zuverlässigkeit und der Verfügbarkeit erfolgt mit der Methode der Differential- oder der Integralgleichungen und führt, im Falle vom Bild 2, zu [2, 3]
|
(4) |
|
(5) |
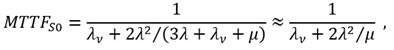
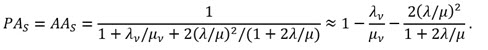
Die Näherungen berücksichtigen, dass in praktischen Anwendungen λ < λv ![]() μ, μv gilt. Das 0 beim S0 deutet an, dass zur Zeit t = 0 alle Elemente neu
sind (Zustand Z0 im Bild 2). Für die Verfügbarkeit gibt man hier nur den stationären Wert PAS an, weil PAS0 (t) sehr schnell zu PAS konvergiert. Man
erkennt, dass das Serienelement Ev die Werte von MTTFSO und PAS bestimmt.
μ, μv gilt. Das 0 beim S0 deutet an, dass zur Zeit t = 0 alle Elemente neu
sind (Zustand Z0 im Bild 2). Für die Verfügbarkeit gibt man hier nur den stationären Wert PAS an, weil PAS0 (t) sehr schnell zu PAS konvergiert. Man
erkennt, dass das Serienelement Ev die Werte von MTTFSO und PAS bestimmt.
Zuverlässigkeitsprüfungen
Zuverlässigkeitsprüfungen sind wichtig, um die bei einer Betrachtungseinheit erreichte Zuverlässigkeit beurteilen zu können. Je früher damit begonnen wird, desto schneller können Schwachstellen, die in den Zuverlässigkeitsanalysen nicht zum Vorschein kamen, entdeckt und mit geringem Aufwand behoben werden. Dadurch entsteht ein Lernprozess, der zu einer gezielten Verbesserung der Zuverlässigkeit und damit zu einem serienreifen Produkt führt. Da Zuverlässigkeitsprüfungen in der Regel aufwendig sind, müssen sie soweit wie möglich mit anderen Prüfungen koordiniert werden. Die Prüfbedingungen sollen nahe bei den reellen Einsatzbedingungen liegen.
Im Folgenden wird man sich auf die Bestimmung und den Nachweis einer konstanten Ausfallrate λ oder von MTBF = 1 / λ beschränken (siehe Anhang A8 und Kapitel 7 von [3] für eine umfassende Darlegung).
Für die Schätzung einer konstanten (zeitunabhängigen) Ausfallrate λ oder einer MTBF = 1 / λ wird in der Regel folgende Prozedur verwendet [2, 3]:
-
wenn in T fest gegebenen kumulativen Betriebsstunden genau k Ausfälle aufgetreten sind,
so ist die Maximum-Likelihood Punktschätzung der unbekannten 1 gegeben durch [2, 3]
|
(6) |
|
das Dach über λ deutet darauf hin, dass es sich um eine Schätzung handelt; die ausgefallenen Betrachtungseinheiten sollen unverzüglich durch neue ersetzt (oder repariert) werden [3, p. 330], das gilt insbesondere wenn die Anzahl der involvierten Betrachtungseinheiten nicht sehr gross ist; infolge der konstanten Ausfallrate λ, kann die kumulative Betriebszeit T theoretisch mit einer beliebigen Anzahl identischer Betrachtungseinheiten zusammengestellt werden (eine praktische Faustregel ist jedoch nicht mehr als etwa λT identische Betrachtungseinheiten zu haben [3, p. 328]); |
|
-
für die Intervallschätzung einer unbekannten Ausfallrate λ, können die Vertrauensgrenzen
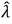 l und
u aus Bild 3 abgelesen werden [2, 3]; dabei ist [
l,
u] das Vertrauensintervall und γ das
Vertrauensniveau (Aussagewahrscheinlichkeit), d. h. die Wahrscheinlichkeit, dass [
l,u] den wahren (unbekannten) Wert von λ überdeckt;
l und
u aus Bild 3 abgelesen werden [2, 3]; dabei ist [
l,
u] das Vertrauensintervall und γ das
Vertrauensniveau (Aussagewahrscheinlichkeit), d. h. die Wahrscheinlichkeit, dass [
l,u] den wahren (unbekannten) Wert von λ überdeckt;
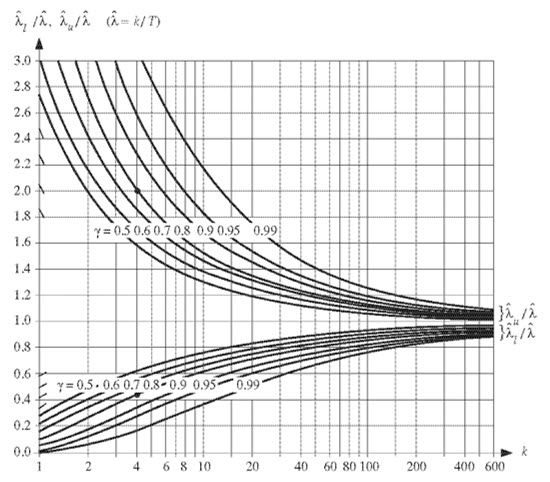

- für praktische Anwendungen kann
|
(7) |
für die Punktschätzung einer unbekannten MTBF verwendet werden (T / (k + 1) wäre erwartungstreu).
Im Zusammenhang mit der Abnahmeprüfung einer Betrachtungseinheit wird oft der Nachweis einer Ausfallrate λ oder einer MTBF = 1 / λ verlangt. Dabei geht es um folgendes:
Die Betrachtungseinheiten sollen mit einer Wahrscheinlichkeit näherungsweise gleich (aber nicht kleiner als) 1 - α angenommen werden, falls die wahre (unbekannte) λ kleiner als λ0 ist, und sie sollen mit einer Wahrscheinlichkeit näherungsweise gleich (aber nicht kleiner als) 1 - β zurückgewiesen werden, falls die wahre λ grösser als λ1 ist (λ 1 > λ0); dabei sind λ1 bzw. λ0 die spezifizierte bzw. die maximal akzeptierbare λ und α bzw. β das Lieferanten- bzw. das Abnehmerrisiko (Risiko für einen falschen Entscheid).
|
Es handelt sich hier um eine Hypothesenprüfung, und der oft verwendete Test ist die sogenannte zweiseitige Einfachprüfung mit α = β . Tabelle 2 gibt die
üblichen Parameterwerte für solche Prüfungen an [2, 3] .
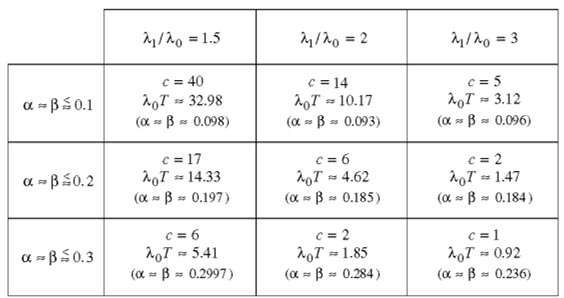
Tabelle 2 Anzahl c der zugelassenen Ausfälle während der kumulativen Betriebszeit T und Werte von λ0T zum Nachweis von λ < λ0 gegen λ > λ1 mit λ1 > λ0 (gilt auch für die Prüfung einer MTBF = 1 / λ und einer unbekannten Wahrscheinlichkeit p, siehe die Bemerkung zur Gl. (6) für die kumulative Betriebszeit T ) [2, 3]
Zusammenarbeit mit der Industrie
Infolge der Vielseitigkeit bzw. Interdisziplinarität der Zuverlässigkeitsprobleme, ist die Zusammenarbeit zwischen allen an einem Projekt beteiligten Linienstellen / Mitarbeitern innerhalb einer Firma sowie zwischen Hochschule und Industrie nicht nur wünschenswert, sondern unbedingt notwendig. An der ETH Zürich war die Zusammenarbeit zwischen dem Lehrstuhl für Zuverlässigkeitstechnik (Reliability Laboratory) und über 30 mittelgrossen und grossen Firmen in der Schweiz und in Europa sehr intensiv und in 5-Jahres-Verträgen auf folgender Basis aufgebaut:
- Vorteile für die Industrie: Teilnahme an der Planung und Realisierung von grossen Forschungsprojekten, kostenlose Lösung von firmenspezifischen Problemen bis zu 10 Tagen pro Jahr und Firma (mit der
nötigen Vertraulichkeit), und Austausch von Erfahrung und Know-how;
- Vorteile für die ETH: CHF 20'000.- pro Jahr und Firma zur Unterstützung bei der Anschaffung von grossen Prüfeinrichtungen, Zugang zu Zuverlässigkeitsproblemen in der Industrie und Inputs für Doktorarbeiten (speziell von grossen Halbleiter-, Geräte- oder Systemherstellern).
Dank dieser Zusammenarbeit wurde ein Laboratorium mit 20 Ingenieuren, Physikern und Technikern (6 von der ETH finanziert, 8 Doktoranden) aufgebaut, wo mit über 6 Mill. CHF hochstehenden Einrichtungen 1, elektrische Prüfungen, Umwelt- und Zuverlässigkeitsprüfungen, sowie Ausfallanalysen an hochintegrierten Schaltungen (VLSI) und komplexen Baugruppen durchgeführt wurden. Es war damit möglich, insbesondere auch mit grossen internationalen Halbleiterherstellern, Qualitäts- und Zuverlässigkeitsprobleme konkret zu besprechen. Diese Zusammenarbeit war für alle sehr fruchtbar, siehe [1] und in die Mitte der Seite IX von [3] für weitere Details.
Ausblick
Neben den Zuverlässigkeitsaspekten in neuen technischen Entwicklungen (Nanotechnologie, Neumaterialien, neue Prozesse usw.), die in Zusammenarbeit mit Fachleuten auf diesen Gebieten gelöst werden müssen, bleiben insbesondere die Untersuchung / Modellierung von fehlertoleranten Strukturen, von vernetzten Systemen, von der Auswirkung multipler Ausfallarten / Ausfallmechanismen, sowie der Softwarequalität, wichtige Forschungsgebiete der Zuverlässigkeitstechnik. Gewiss trägt die Zuverlässigkeitstechnik zur Verbesserung der Nachhaltigkeit bei. Die Technik allein reicht aber nicht, trotz künstlicher Intelligenz und der Hoffnung auf die Eroberung anderen Planeten2, alle anstehenden grossen Probleme der Menschheit zu lösen. Konkrete, auch wenn zum Teil idealistische Vorschläge dazu wurden 2019 dem Club of Rome unterbreitet [4], siehe auch [5] für erste Hinweise.
Literatur
[1] |
Birolini A., Reliability Engineering: Cooperation between University an Industry at the ETH Zürich, Quality Engineering, Vol. 8, No. 4, 1996, pages 659-674. |
| [2] | Birolini A., Zuverlässigkeit von Geräten und Systemen, Springer 1997 (als 5. Aufl., incl. die 2. bereinigte Aufl. 1990, von Qualität und Zuverlässigkeit technischer Systeme, Springer, 1. Aufl. 1985).
|
| [3] | Birolini A., Reliability Engineering: Theory and Practice, 8 th Edition, Springer 2017 (1 st Ed. 1994).
|
| [4] | Birolini A., 10 concrete suggestion for a new, sustainable world (in German), Birolini.ch , 13 April 2019.
|
| [5] | Bacivarov I. C., Lesson from a life dedicated to reliability: Interview with Prof. A. Birolini, Quality Assurance (Asigurarea Calitatii), Vol. 16, No. 64, 2010, pages 5-7.
|
________________________________
| 1) |
U. a. eine Sentry S 50 mit 128 Pins, ein IDS 5000, eine grosse Kammer für thermische Zyklen mit bis zu 80°C/min innerhalb der Prüflinge, und Einrichtungen für umfassende Ausfallanalysen.
|
| 2) |
Bezüglich künstlicher Intelligenz bleibt die Gefahr von Roboten überrollt zu werden hypothetisch, denn man kann immer noch den Stecker ziehen; zur Eroberung anderer Planeten, werden die nötigen Ressourcen und Energien, sowie jahrelange Reise, Grenzen setzen.
|